1. Overview
1.1 What is Epistemic Exploration?
Epistemic exploration is the agent's capacity to actively acquire information that reduces its uncertainty about the world, convert that reduction into durable policy improvement, and keep future acquisition possible.
Unlike undirected exploration (e.g., ε-greedy), epistemic exploration is intentional, belief-driven, and multi-scale: the agent reasons about which actions are most informative and plans multi-step information-gathering strategies across reasoning trajectories, tool-use policies, embodied sensorimotor loops, world-model rollouts, and multi-agent coordination protocols.
1.2 Three Criteria
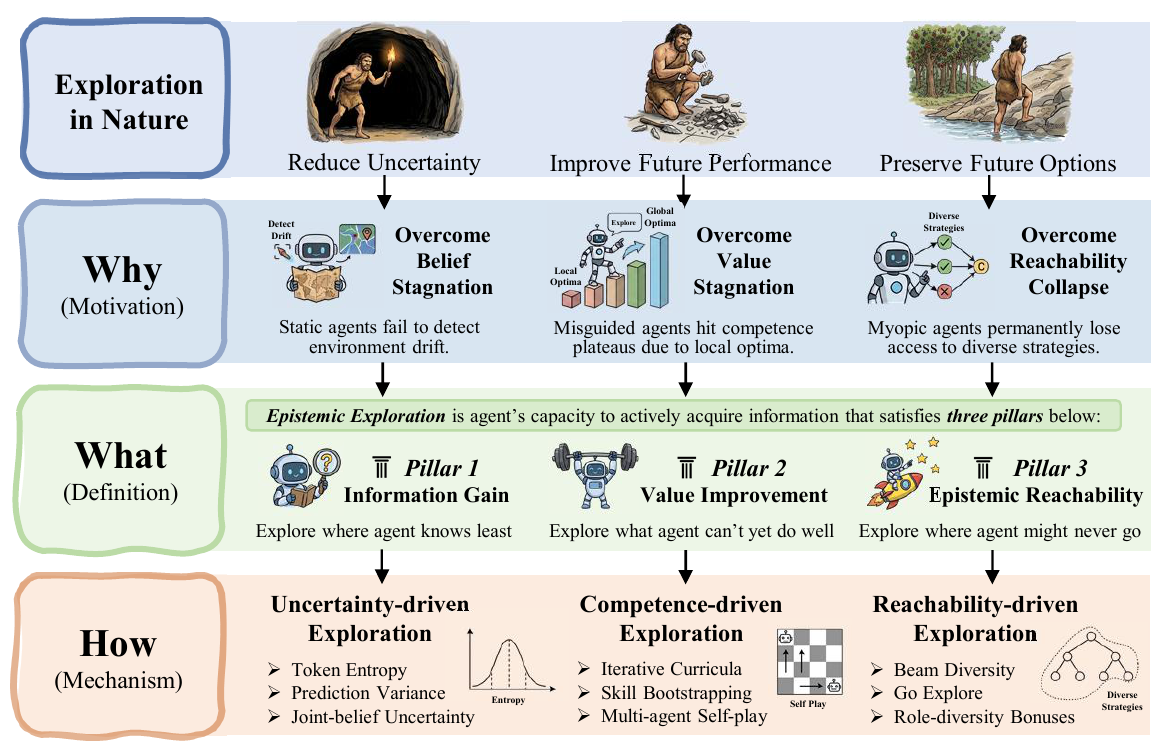
We ground epistemic exploration in three jointly necessary criteria, each addressing a distinct failure mode of static optimisation:
C1
Information Gain
Actively reduces epistemic uncertainty via belief-updating observations
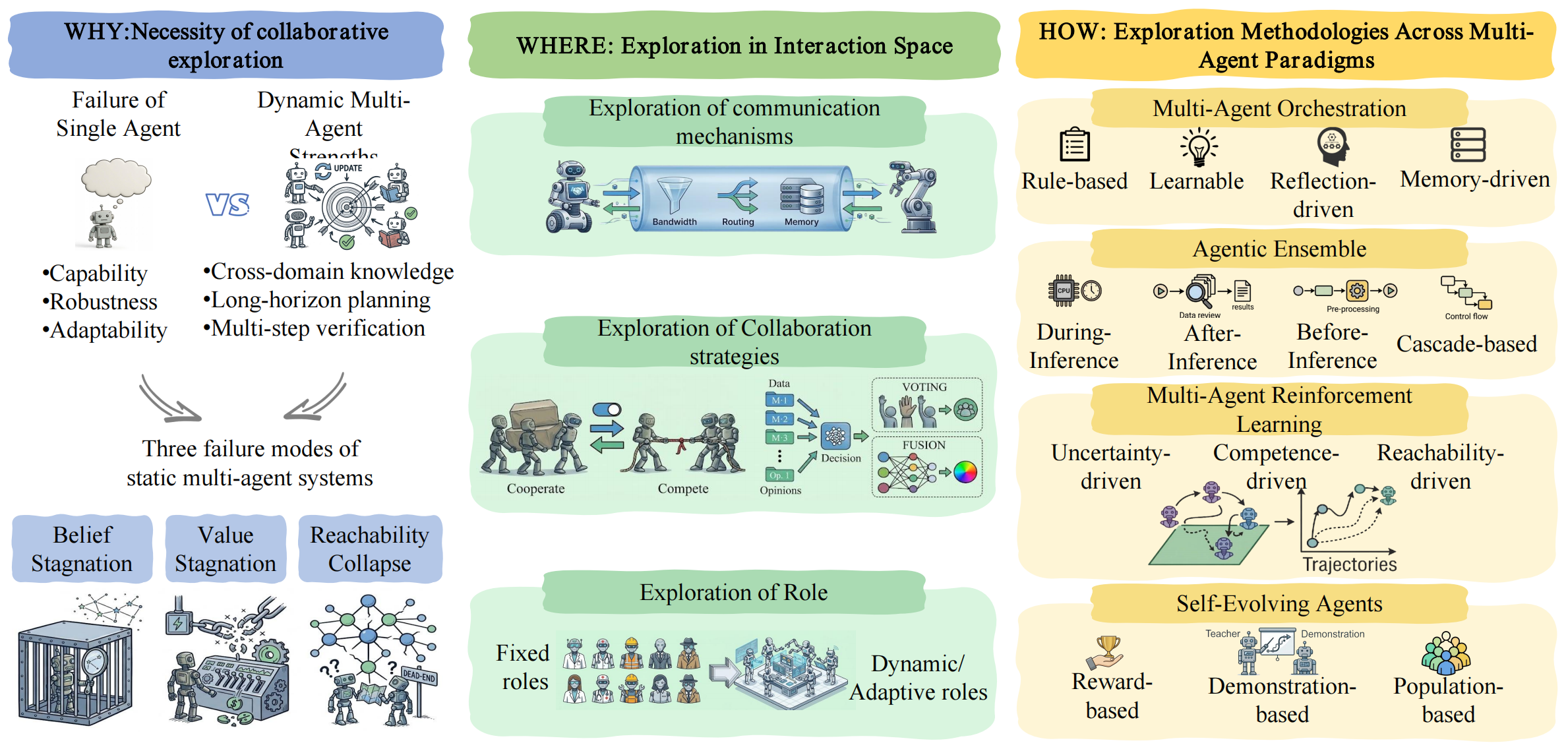
- Failure Mode: Belief Stagnation — frozen internal model under distribution shift
- Explores: ...where it knows least
C2
Value Improvement
Converts new information into durable policy improvement
- Failure Mode: Value Stagnation — local optima lock-in, surrogate misalignment
- Explores: ...what it cannot yet do well
C3
Epistemic Reachability
Preserves positive visitation over belief-consistent regions
- Failure Mode: Reachability Collapse — irreversible contraction of behavioural diversity
- Explores: ...where it might otherwise never go
These form a closed loop: gain information → convert to value → keep the capacity to gain information alive → ...
1.3 Unified Epistemic Exploration Objective
The three criteria combine into a single constrained objective:
$$
\pi_{\mathfrak{A},t}^{*}
\;=\;
\underset{\underbrace{\pi_{\mathfrak{A}} \,\in\, \Pi_{\mathrm{reach}}(b_t)}_{\text{Reachability (C3)}}}{\arg\max}\;
\underbrace{\mathbb{E}_{\theta \sim b_t} \Big[V^{\pi_{\mathfrak{A}}}_\theta(s_t, h_t)\Big]}_{\text{Value Improvement (C2)}}
\;+\;\beta\;\cdot\;
\underbrace{\mathbb{E}^{\pi_{\mathfrak{A}}}_{b_t} \left[\sum_{t'=t}^{\infty} \gamma^{\,t'-t}\,\mathcal{U}(s_{t'}, a_{t'};\, b_{t'})\right]}_{\text{Information Gain (C1)}}
$$
where $\mathcal{U}(s, a;\, b) = I(\theta;\, s', r \mid s, a, b)$ is epistemic uncertainty, and $\Pi_{\mathrm{reach}}(b_t)$ is the reachability-feasible policy set.
Information-Gain Term (C1)
Expected cumulative epistemic uncertainty the agent anticipates resolving along its trajectory.
Value Improvement (C2)
Expected cumulative reward under current beliefs; what a pure exploiter would maximise.
Reachability (C3)
Visitation must remain over every region plausibly relevant under beliefs, preventing short-term gains from foreclosing future learning.
1.4 Five-Level Trajectory Toward AGI
We propose exploration as the transition mechanism between five levels of increasing agent sophistication. Each level introduces a qualitatively new exploration space that the previous level cannot access:
| Transition |
Exploration Space |
What Becomes Explorable |
| L1 → L2: Responder → Reasoner |
Reasoning space |
Hypotheses, alternative reasoning trajectories, latent thought representations; self-verification and revision |
| L2 → L3: Reasoner → Agent |
Interaction space |
Embodied perception, tool invocation, memory management, closed-loop action under partial observability |
| L3 → L4: Agent → Prospector |
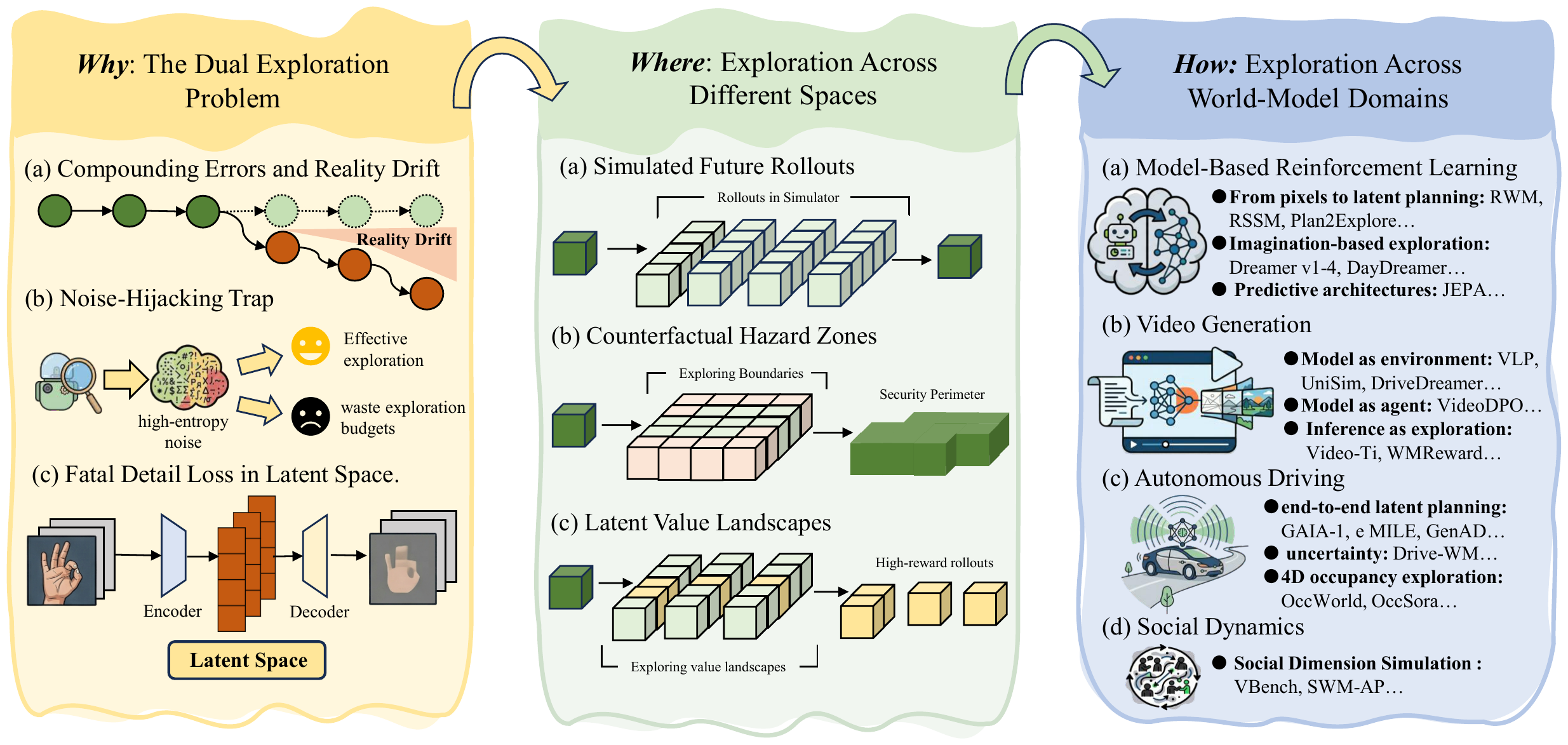
Imagination space |
Counterfactual futures in learned world models; the dual exploration problem across real and imagined environments |
| L4 → L5: Prospector → Ecosystem |
Coordination space |
Communication topologies, co-evolving role specialisations, shared representations, collaborative strategies |
1.5 3×5 Taxonomy
Our survey is organized as a 3×5 taxonomy crossing three signal-driven methodologies with the five levels:
|
L1 Responder |
L2 Reasoner |
L3 Agent |
L4 Prospector |
L5 Ecosystem |
| Uncertainty-Driven |
—(single forward pass; no internal search) |
Token / step entropy, entropy-guided branching |
Active SLAM, prediction variance, pose uncertainty |
Ensemble disagreement in latent world models |
Inter-agent disagreement, joint-belief uncertainty |
| Competence-Driven |
—(no learning loop at inference) |
Difficulty-adaptive curricula, self-verification, self-play |
Skill bootstrapping, goal-conditioned self-play |
Imagination-based skill discovery, learning-progress curricula |
Emergent multi-agent self-play, co-evolving curricula |
| Reachability-Driven |
—(fixed output manifold) |
Beam diversity, anti-repetition, KL-to-reference trust regions |
Go-Explore, coverage-maximising curricula |
Latent-space diversity bonuses, action-entropy regularisation |
Role-diversity bonuses, anti-convergence on coordination topologies |